Clusters
You may have heard of the town, Fallon, Nevada. It's children have an enormous incidence of a particular cancer, acute lymphocytic leukemia (ALL). While ALL is not exactly a rare cancer, there are perhaps 2, 600 case per year in the US, the sparsely populated Fallon area had 14 cases diagnosed in the five years between 1997 and 2002. [More information on the issue.] This triggered several investigations into the region looking for a cause. No definite cause has been established to date, however there was shown to be high levels of tungsten in the area's drinking water. Had there been a large tungsten refiner in the area, the next step would have been a billion dollar lawsuit, however it appears that nature put the tungsten in the water- I'm sure the bus loads of lawyers that poked around Fallon must have been disappointed - it's not a prime vacation location. Tungsten however is a chief material in incandescent light bulb filaments. Should be we ban light bulbs? [The decision was made to replace tungsten filament bulbs, that were made in America and have no evidence of toxicity, with mercury laden bulbs that are made, for the most part, in China. I don't recall reading any risk assessment being made.]
Disease clusters, especially of cluster of cancers, may be caused by several things. First, there may actually be some cause of the cluster. Here are two sites that you might find interesting. First a colorful story.
Now from the UK where the Sellafield region has a cancer cluster and Sir Black concluded it was not due to local nuclear power plant::
After the discovery of the Sellafield 10-fold excess child leukaemia cluster Sir Douglas Black's report exonerated the radiation, but Black did not seem persuaded. Like any intelligent outsider to the issue he was clearly confused by a failure to link the largest source of radiation in Europe to a local cluster when radiation was the only proven cause of leukaemia. the UK.
Note however the hyperbole and contradiction with the Fallon story, radiation is not the only cause of leukemia. Here is a balanced report on cancer clusters from an agency perspective.
And here is it in more technical language:
Before a cluster can be considered "true," epidemiologists must show that the number of cancer cases which have occurred is significantly greater than the number of cases that would be expected, given the age, gender, and racial distribution of the group of people at risk of developing the disease. However, it is often very difficult, if not impossible, to accurately define the group of people who should be considered "at risk." One of the greatest pitfalls of defining clusters is the tendency to extend the geographic borders of the cluster to include additional cases of the suspected disease as they are discovered. The tendency to define the borders of a cluster on the basis of where one knows the cases are located, rather than to first define the population and then determine if the number of cancers is excessive, creates many "clusters" that are not genuine.
For this and a variety of other reasons, most reported cancer clusters are not shown to be true clusters. Many reported clusters do not include enough cases for epidemiologists to arrive at any conclusions. Sometimes, even when a suspected cluster has enough cases for study, a true statistical excess cannot be demonstrated. Other times, epidemiologists find a true excess of cases, but they cannot find an explanation for it. For example, the suspected carcinogen may cause cancer only under certain circumstances, making its impact difficult to detect. Moreover, because people change residence from time to time, it can be difficult for epidemiologists to identify previous exposures and find the records that are needed to determine what kind of cancer a person had--or if it was cancer at all. From: http://imsdd.meb.uni-bonn.de/cancernet/600358.html from the National Cancer Institute.
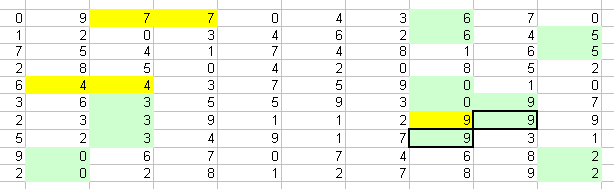
So what causes cancer clusters? Before we get into math, (if I can't avoid it) look at this table. It is generated in Excel using the random number generator. Each of the 100 cells contain a number between 0 and 9 generated absolutely randomly:
Where adjacent cells in a row have the same number, the cells are highlighted in yellow. Where cells in a column are the same they are in green, and where they are both a row and column, they are boxed. Since each cell has 4 neighbors and there are 10 random numbers that can go in those cells, we would not be amazed to find that 4/10 or 40% of the cells have an identical neighbor. Here my knowledge of statistics and probability are inadequate, but look at the 3's in the third column and the 9's in columns 8 and 9. The four 9's especially "look too close together." Now drop back and look at the three center columns that have no matches, as does first column. The matches seem concentrated in only half of the 10 columns: 2,3,8,9 and 10. Why are columns 5,6, and 7 devoid of matches? My answer is simply that truly random distributions are not smooth, they are lumpy.
We often use statistics to take a sample of a population, then make some inference about the whole population. We need to do this when it is impossible or impractical to sample the entire population. For example, if you wanted to determine something about the population of a city, ideally you would list all the city residents, assign them each a number, then use a random number generator to select an appropriate sample size, than only test the sample (people selected). If the sample was chosen randomly, the result might be quite predicative of the total population. In statistics, it is sometimes useful to sample in clusters, rather than completely randomly. Continuing with the city population example, you get a list of all the apartments in the city, then select certain apartments, then sample all the residents in those apartments. Although the statistics and resulting confidence intervals are a little more complicated than the completely random sampling, sampling by clusters can derive useful results. The key to the system is how the clusters, apartments, were selected. If you had a large number of apartments in the city, then selected the apartments completely at random, the results would probably be as useful as a completely random sampling. However you can quickly see that if you selected the apartments or clusters with bias, perhaps just the apartments close to your office building, you might get completely erroneous results. For disease clusters, we do exactly that, we start the cluster analysis with a completely bias sample, those locations with the diseases is reported as being more prevalent, so standard statistics based on random clusters does not apply.
Another aspect of the disease cluster relates to human concerns, compensation, and medical diagnosis. If high incidents of a rare disease are reported in the local media, doctors will get a flood of patients demanding to be examined for that particular disease. This may lead to finding incidents of a disease that, if left untreated, might not have become clinically significant or might have cured itself. It may accelerate the incidence, by reporting disease at an earlier stage. Media reports may lead some susceptible people to believe they have symptoms which may also lead to an epidemic of misdiagnosis. Notoriety and/or political pressure may lead to adjusting the geographic boundaries to encompass incidents of the disease. The possibility of compensation may also lead people who briefly reside in an area to demand inclusion in the study area.
The existence of an apparent cluster of a disease geographically associated with an environmental contaminant is not in itself scientific proof that the contaminant caused the cases in the cluster. (Lawyers and media do not require scientific proof of causation.) Then again, it may really be the tungsten. More research is needed.